
Introduction: When patching becomes a boardroom issue
Two incidents, one message: Delay or rush a critical patch, and the consequences can be exponential.
In 2023, a zero-day vulnerability in MOVEit Transfer led to a breach that exposed the personal data of over 66 million people across 2,500 organizations.
Just a year later, a faulty update from CrowdStrike’s Falcon agent brought down 8.5 million Windows machines worldwide—grounding flights, halting bank operations, and triggering what some dubbed as “the largest outage in IT history.”
One was an exploit of an unpatched flaw. The other was a rushed security update gone wrong. But the common thread is clear: patch management is no longer a back-office concern. It’s an enterprise risk with massive operational consequences.
This data reinforces the urgency:
- 78% of organizations report delays in patching critical vulnerabilities
- 62% have suffered incidents due to known but unpatched flaws
The stakes are no longer theoretical. Today, patching isn’t just about security hygiene; it’s about protecting your customers, your continuity, and your reputation.
The message of this article: patch promptly and carefully, or prepare to pay in data loss, downtime, and brand damage.
MOVEit recap: A masterclass in the cost of delayed patching
In May 2023, a zero-day vulnerability in Progress Software’s MOVEit Transfer became the launchpad for one of the most far-reaching data breaches in recent memory. The flaw, a critical SQL injection bug (CVSS 9.8), was exploited by the Clop ransomware gang before any patch existed.
By the time Progress issued a fix on May 31, the damage had already spread across industries and continents. The blast radius was staggering!
About 2,500+ organizations experienced the breach, 66+ million individuals were impacted, and victims included household names like Shell, British Airways, and Morgan Stanley, plus multiple U.S. federal agencies and leading universities.
The breach exposed deeply sensitive data—from Social Security numbers to health records— triggering widespread legal, financial, and regulatory fallout. Some companies spent over $20 million in response. Total damages, with remediation and liability costs still mounting, are reported to exceed $12 billion.
The U.S. SEC even launched an investigation into Progress Software’s vulnerability handling.
The root cause? A missed patch window. Or rather, a patch that didn’t exist soon enough.
The MOVEit incident is a cautionary tale: when patching lags behind exploitation, a routine software flaw becomes an emergency. In this case, hours mattered. Those who patched immediately or took systems offline were spared. Others had to pay the price.
The lesson: Visibility and speed in patch management aren’t just good practice, they’re a frontline defense against catastrophic risk.
CrowdStrike recap: When a security patch becomes a risk
On July 19, 2024, a routine configuration update from CrowdStrike’s Falcon Sensor triggered one of the largest IT outages in history. A bug in the kernel-level Windows driver led to mass system crashes. Blue screens of death appeared across 8.5 million devices globally.
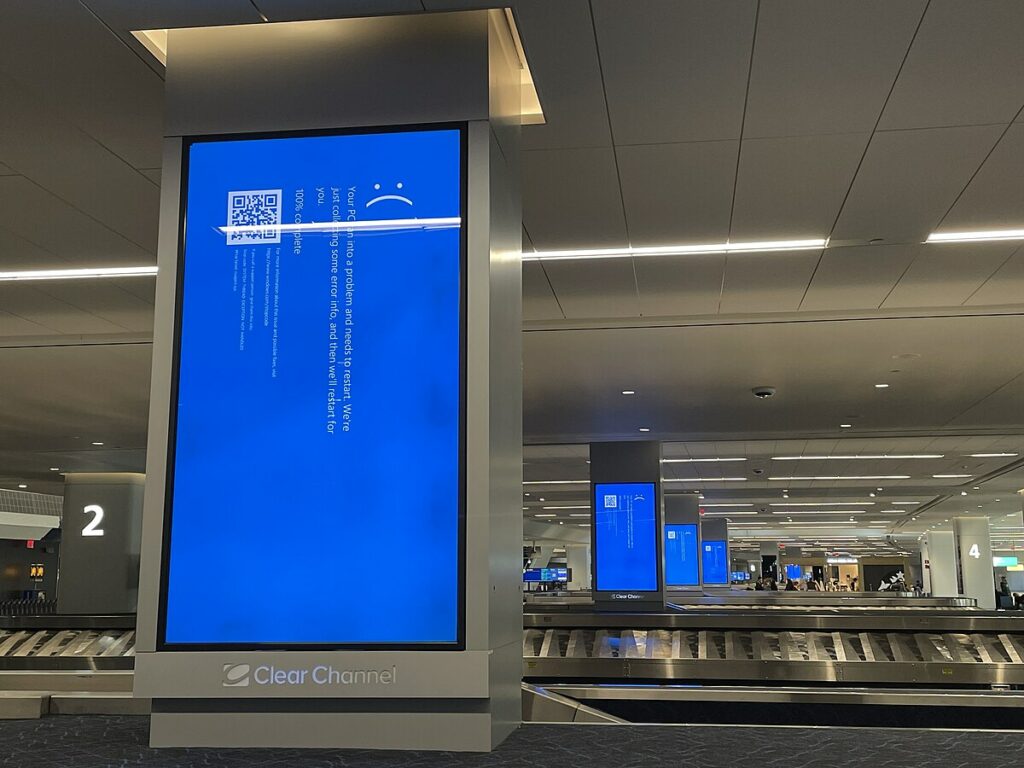
There was no phased rollout. No safety net. The update hit banks, airports, hospitals, and governments simultaneously. Flights were grounded. Retail systems failed. Business operations collapsed. Early estimates pegged global damages between $5–10 billion, all from a patch meant to “protect”.
The root cause? A single, untested config file, pushed at scale without staging or rollback. Developers hadn’t accounted for outdated formats or regression testing. And because Falcon runs deep in the Windows OS stack, the crash took down entire systems instantly.
The irony was hard to miss: A security tool, designed to prevent chaos, became the source of it.
This incident reframed the patching conversation. Speed without safeguards is a risk. No matter how trusted the source, even security updates must be treated with zero-trust discipline — tested, staged, and monitored before wide deployment.
The takeaway for IT leaders is clear: patch fast, yes. But always patch smart. Without controls like phased rollouts and rollback mechanisms, your next update could be your next outage.
Patch management is a double-edged sword
The MOVEit breach and the CrowdStrike outage offer a stark lesson: Patching can either protect you or break you, depending on how it’s done.
Delay a patch, and you risk a breach. Rush a patch, and you risk a system-wide outage. This is the paradox IT leaders face daily. As vulnerabilities multiply and infrastructure grows more complex, the margin for error in patch management is razor-thin.
Why is patching so hard at scale?
- You can’t patch what you can’t see. Asset sprawl, shadow IT, and incomplete inventories mean many endpoints remain invisible, and therefore, vulnerable. NIST emphasizes continuous asset discovery as the foundation for secure patching.
- Dependencies are fragile. In today’s interconnected stacks, one update can break another. Fear of downtime often delays even critical patches. The CrowdStrike outage proved that one misstep can take down global infrastructure in minutes.
- Silos and fragmentation slow everything down. Without a unified patch strategy across business units, gaps emerge. Some systems stay outdated for months, increasing exposure to known threats.
- Manual patching doesn’t scale. IT teams are stretched thin. Many still rely on manual workflows, with patch cycles taking weeks or even months — time attackers are eager to exploit.
- No rollback, no recovery. When a patch fails, many organizations have no safe fallback. No backups. No snapshots. No playbook. The result? Chaos.
Patching is no longer just IT hygiene; it’s operational resilience. And that means rethinking how we approach it: prioritize visibility, automate with guardrails, build rollback plans, and align security with ops.
The lesson is clear: patching isn’t optional. However, reckless patching isn’t survivable either.
You must balance speed with safety and treat updates like any other high-risk deployment. Because in today’s environment, patching isn’t just about fixing software, it’s about protecting trust.
Lessons for modern IT teams
Facing these challenges, how can organizations patch smarter? Below are five key lessons drawn from these incidents and industry best practices:
Lesson 1: Visibility first
You can’t patch what you can’t see. In today’s sprawling IT environments, that’s a dangerous blind spot.
Before deploying a single patch, ask yourself: “Do we have a complete, real-time inventory of every endpoint, OS, and software asset across our environment, including cloud workloads, shadow IT, and third-party apps?” If the answer isn’t a confident “yes,” patching is already on shaky ground.
The MOVEit incident proved that unknown systems become silent liabilities. One untracked application can unravel enterprise-wide security. That’s why visibility isn’t just a technical prerequisite; it’s a strategic imperative.
Modern IT teams need more than static spreadsheets. They need automated discovery tools, real-time software bills of materials (SBOMs), and unified dashboards that track patch status across every OS and device type.
NIST guidance advises organizations to “constantly maintain up-to-date software inventories” because inventories that are even a few weeks old are quickly outdated in a dynamic environment.
Visibility isn’t just step one. It’s the foundation for every smart patch decision you’ll make. Without it, you’re not managing risk—you’re guessing.
Lesson 2: Prioritize by risk
In an ideal world, every vulnerability gets patched instantly. In the real world, prioritization is survival.
Modern IT environments are too vast and too dynamic to patch everything at once. That’s why risk-based patching is no longer optional; it’s the only responsible path forward.
Not all vulnerabilities are created equal. A CVSS 9.8 exploit actively being used in ransomware campaigns demands immediate attention. Whereas, a moderate flaw in an isolated internal tool? That can wait, though not forever.
An effective patch strategy starts by triaging based on risk factors, such as:
- Severity scores (CVSS)
- Active exploitation in the wild (use CISA’s KEV catalog)
- Business criticality and exposure of the affected system
- Potential blast radius, if the system is compromised
The MOVEit breach was a textbook case: a high-severity, internet-facing vulnerability with devastating reach. Those who acted fast minimized damage. Those who didn’t, joined a global breach tally.
Use a formal patching SLA matrix. Critical threats should be patched within 24 hours, high within 72 hours, and so on, adapted to your environment and appetite for risk. Build a matrix that fuses technical data with business impact, and update it dynamically as threat intelligence evolves.
Prioritization isn’t procrastination, it’s precision. It’s how mature IT organizations stay secure without setting the world on fire with every patch cycle.
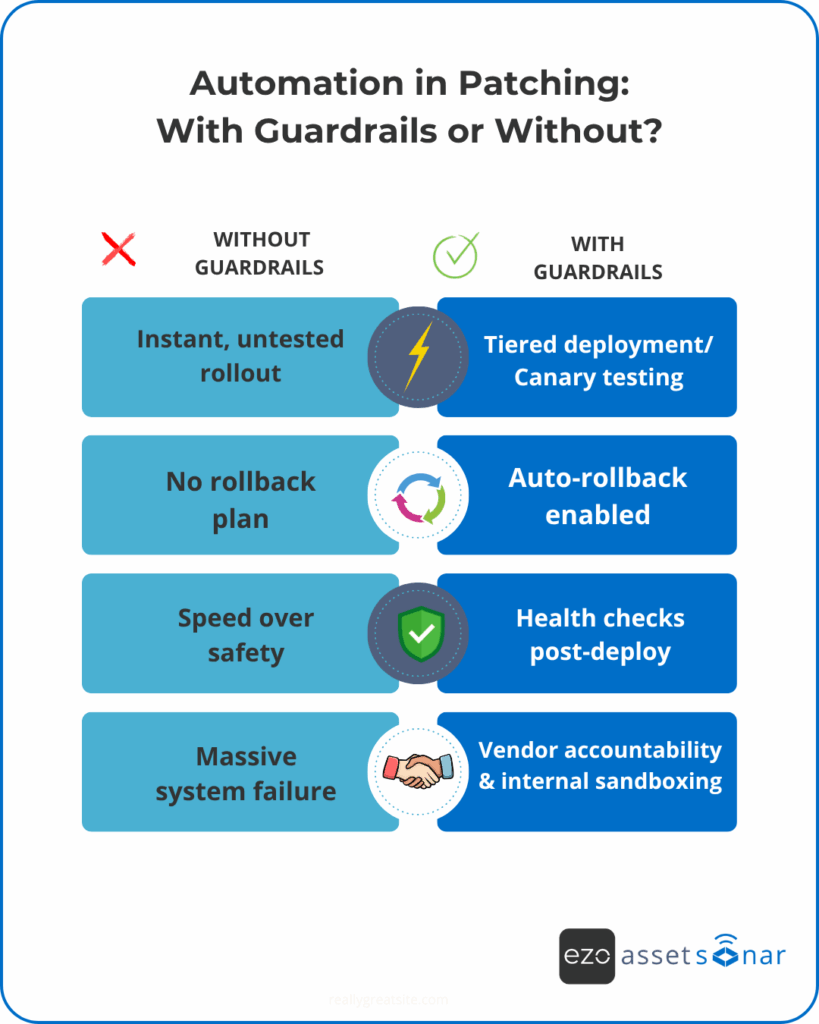
Lesson 3: Automate, but with guardrails
Automation is the only way to keep pace with today’s patching demands. However, if left unchecked, it can also scale your mistakes.
Enterprise environments don’t have the luxury of manual patching. With thousands of endpoints, dozens of platforms, and constant threat exposure, automation is non-negotiable. It reduces human error, shrinks the window of vulnerability, and frees up overburdened IT teams.
But the CrowdStrike incident is a wake-up call for prudent IT teams: a single bad update, pushed instantly to millions of machines, can trigger perhaps the largest IT outage imaginable. Not because automation is bad, but because it lacks safety rails.
Here’s the modern patching mantra: Automate deployment, not detonation.
Built in tiered rollouts and canary deployments. Push updates first to a controlled test group — a handful of machines, not your entire network.
Monitor. Analyze. Only then scale.
Most patching tools support rings, waves, or progressive rollout logic.
Here’s what you should do to make sure that guardrails go beyond rollout strategy:
- Implement auto-rollback mechanisms for failed updates.
- Use health checks post-deployment. If a patch tanks performance or crashes systems, pause and revert.
- Require approvals for high-impact systems. Not to slow things down, but to ensure that the eyes of key stakeholders are on the blast radius.
And don’t skip vendor accountability! Hold your patch providers to a higher standard of pre-release testing. But also own your part. Build sandbox environments and fail-safes into your patch update pipeline.
The lesson is clear: automation without control is a liability. But with the right balance, it becomes your best defense — fast, resilient, and surgical.
Lesson 4: Test before you trust
Speed matters. But trust without verification is reckless.
The CrowdStrike incident was a painful reminder: one untested patch can bring down many of the world’s largest tech-dependent systems. In their case, a simple config pushed without validating older Windows environments triggered a global meltdown.
And they aren’t alone. Countless organizations skip testing in the race to patch fast.
Every patch, no matter how routine, carries risk. That’s why smart IT leaders should treat testing as a non-negotiable control.
Start with the basics:
- Maintain a staging environment that mirrors production, even partially, to trial updates before they go wide.
- Run smoke tests on mission-critical apps. After the patch, does your ERP still load? Is latency stable on your databases? Don’t wait to find this out in production.
- For lean teams, adopt canary testing: patch a handful of user devices or VMs, monitor for 24–48 hours, then expand.
- Watch the community. When Patch Tuesday hits, pause and listen. Reddit, vendor forums, and CISA bulletins often flag issues within hours.
And don’t just test the patch, test your rollback plan too. Can you quickly revert or restore from backup if something breaks? If not, the real risk isn’t the patch, it’s your lack of a parachute.
Testing doesn’t have to be time-consuming. Even an hour of validation is better than blind deployment. Techniques like feature flags and blue-green deployments let you move fast and safely.
The real mindset shift? Treat patches like change, because that’s what they are. And every change in production should earn its way there.
Trust your vendors, but verify in your environment. That’s how modern IT teams stay both agile and accountable.
Lesson 5: Monitor and validate continuously
Applying a patch is just the beginning. True resilience comes from continuous validation—confirming the patches worked, catching issues early, and maintaining full visibility across your environment.
Don’t rely on silence as a success signal. Monitor for anomalies post-patch—slowdowns, errors, reboot failures—and act fast. Confirm that vulnerabilities are actually closed through scans or test exploits. Validate system health, not just patch status.
Plus, maintain a live dashboard that tracks compliance, failures, and overdue patches. Integrate it with your SIEM or ITSM tools to enforce internal SLAs. If you conduct regular audits, they can also uncover false positives e.g., machines that were marked as patched but still showed active vulnerabilities that slipped through the cracks.
This vigilance is key for both security and compliance (e.g., ISO 27001, HIPAA). Monitoring provides the evidence that regulators require and the insights your team needs to improve.
Treat patching as a continuous cycle: Deploy, verify, learn, and refine. The organizations that caught post-patch issues during MOVEit and CrowdStrike had one thing in common: continuous visibility. Without it, you’re not secure; you’re just unaware.
Recap: What a resilient patch management strategy looks like
Today’s patch management is no longer about reacting to the latest CVE. It’s about building resilient systems that anticipate risk, contain fallout, and recover fast.
Here’s what defines a best-in-class patch management strategy:
1. Continuous asset visibility
Start with a centralized, automated inventory of all endpoints, servers, and applications. Visibility is the foundation. If you can’t see it, you can’t patch it.
2. Integrated vulnerability intelligence
Layer in real-time vulnerability scanning and threat feeds (like NIST or CISA advisories). This lets you prioritize action before exploits hit, even enabling preemptive controls before official patches are released.
3. Policy-driven patch workflows
Define a clear patch policy that dictates how patches are prioritized, tested, and rolled out. Segment endpoints by risk and align rollout schedules with business operations. Differentiate between routine and emergency procedures and enforce them accordingly.
4. Staging and testing as a standard practice
Test before trust. Use staging environments or pilot groups to validate stability before full deployment. Even lightweight sandboxing can catch issues before they escalate.
5. Phased deployment with rollback safety nets
Roll patches out gradually—5%, then 20%, then full deployment. If a patch fails, revert fast. Automation helps here: revert to a known-good image or AMI with minimal disruption.
6. Centralized monitoring and compliance dashboards
Use a unified platform to track patch status, coverage, and drift from policy. Real-time visibility and automated compliance reporting are essential for IT teams and auditors alike.
7. Use modern tooling that’s built for scale
Adopt patch management tools that offer:
- Multi-OS and third-party app coverage
- Zero-touch automation with scheduling
- ITSM/change management integration
- Built-in rollback and prioritization based on risk
- Reporting for SLA compliance
The next time a critical zero-day drops, your success depends on preparation—not panic. With strong visibility, intelligent automation, and fail-safes in place, patching can become a strategic advantage for you. Resilience in patch management is the outcome of smart process design and the right tools.
Final word: From reactive to proactive
Patch management is no longer back-office maintenance; it’s frontline defense. The MOVEit breach exposed the cost of delayed action. Whereas the CrowdStrike outage revealed the danger of rushing in blindly. Both underscore a core truth: patching without strategy is a liability.
The answer isn’t to freeze or to sprint, it’s to prepare. Proactive patch management means knowing your environment, enforcing clear policies, testing before rollout, and investing in tools that give you visibility and control. It should be a leadership priority.
As the NIST framework reminds us, patching is “a standard cost of doing business”—akin to changing the oil in your car.
Skip it, and you’re headed for a breakdown.
Organizations that handled MOVEit or CrowdStrike best weren’t lucky. They were ready. They had inventories, processes, and rollback plans in place before disaster struck.
The lesson? Don’t wait for headlines to take patching seriously. Build muscle now. Because resilience isn’t reactive, it’s engineered.
Is your patch strategy ready for the next crisis?

MOVEit and CrowdStrike weren’t flukes; they were warnings. Now’s the time to audit your patching strategy.
Do you have complete visibility? Do you carry out risk-based prioritization? Do you automate patch deployments, but with safeguards? Do you have a tested rollback plan?
Don’t wait for a breach or an outage to expose the gaps in your patch strategy. Resilient patch management can be a competitive edge in today’s threat landscape. You can either patch smart or pay later.
See how AssetSonar can help you build a resilient patch management strategy with automated discovery, risk-based prioritisation, and scheduled patch deployments.
Frequently Asked Questions
1. What happened in the MOVEit breach?
In May 2023, a critical SQL injection vulnerability in MOVEit Transfer allowed the Clop ransomware group to exfiltrate data from over 2,500 organizations, affecting more than 66 million individuals.
2. How did the CrowdStrike outage occur?
In 2024, a faulty update to CrowdStrike’s Falcon agent caused a global outage, impacting 8.5 million Windows systems and disrupting operations across various sectors.
3. What are the risks of delayed patching?
Delaying patches can expose systems to known vulnerabilities, leading to potential data breaches, legal consequences, and reputational damage.
4. What are the risks of rushing patches?
Implementing untested patches can introduce new issues, causing system outages and operational disruptions, as seen in the CrowdStrike incident.
5. How can asset visibility improve patch management?
Comprehensive asset discovery ensures that all endpoints are accounted for, allowing for timely and targeted patch deployment.
6. Why is patching complex at scale?
Large, interconnected IT environments have numerous dependencies, making it challenging to apply patches without causing system conflicts or downtime.
7. How can automation aid in patch management?
Automated patching tools can streamline the deployment process, ensuring timely updates while reducing human error.
8. What role does testing play in patching?
Testing patches in a controlled environment helps identify potential issues before deployment, minimizing the risk of system disruptions.
9. How can continuous monitoring enhance patch effectiveness?
Ongoing monitoring allows for the detection of anomalies post-patching, enabling quick identification and resolution of any emerging issues.
10. How can IT asset management support patching efforts?
Solutions like AssetSonar provide real-time visibility into asset status, aiding in efficient patch deployment and compliance tracking.
11. What are the consequences of a patching failure?
Failure to patch can lead to security breaches, data loss, operational downtime, and legal ramifications, as demonstrated by the MOVEit breach.
12. How can organizations prepare for future patching challenges?
Developing a proactive patch management strategy, including regular audits and risk assessments, can mitigate potential issues.
13. What lessons can be learned from the MOVEit incident?
The MOVEit breach underscores the importance of timely patching and the risks associated with delayed updates in critical systems.
14. What lessons can be learned from the CrowdStrike outage?
The CrowdStrike outage highlights the need for thorough testing and validation of patches to prevent unintended disruptions.
15. How can organizations balance security and operational continuity?
Implementing a structured patch management process that includes risk assessment, testing, and monitoring can help balance security needs with operational stability.




