
The vulnerability overload problem
It’s 7:30 AM in the IT operations war room. Overnight, the security feed has lit up with hundreds of newly published vulnerabilities. Severity ratings are all over the map—some marked “critical,” others tagged as “medium,” and more than a few still awaiting assessment.
Your patch management team is already stretched thin, juggling last week’s backlog while fielding urgent tickets from business units. This scene plays out daily for IT managers everywhere.
The challenge is no longer finding vulnerabilities; it’s knowing which ones truly matter for your business and acting on them before they become a problem.
“We’re constantly firefighting. Zero-day disclosures or urgent vendor patches can derail all planned work, and with only a handful of people, we can’t possibly patch everything”, says the IT & Cybersecurity Manager at a defense contractor firm.
Floods of CVE listings and “high severity” alerts often mask a more important truth: not every vulnerability poses the same level of risk in your unique environment. Some may target systems you don’t even use, while others that are buried halfway down the list could be the very flaw an attacker exploits to breach your defenses.
This gap between awareness and action is where organizations struggle the most. Knowing a vulnerability exists is not the same as knowing:
- Whether it affects your infrastructure,
- How urgently it needs to be patched, and
- What dependencies and business risks are at stake.
In this guide, we’ll cut through the noise.
We’ll break down two pillars of vulnerability intelligence, i.e., NIST’s National Vulnerability Database (NVD) and the Common Vulnerability Scoring System (CVSS), and show how to connect them to real-world patching priorities.
More importantly, we’ll walk through how to turn daily vulnerability feeds into a business-focused patch management strategy that aligns with your operational realities.
By the end, you’ll have a clear, repeatable approach to:
- Identify vulnerabilities that matter to your systems, not just in theory.
- Prioritize fixes based on actual risk, not generic severity scores.
- Reduce wasted effort on low-impact patches while tightening defenses where it counts.
Brace yourselves—this is going to be a long guide. But who’s complaining? It’s meant to help you set up a comprehensive patch management strategy so you aren’t always firefighting vulnerabilities.
Let’s start off with the building blocks first: NIST and CVSS.
What is NIST’s role in patch management strategy?
It’s one thing to know that a vulnerability exists; it’s another to know where that information comes from, how reliable it is, and how quickly you can act on it. For most IT and security teams, the starting point is the National Vulnerability Database (NVD), maintained by the National Institute of Standards and Technology (NIST).
The NVD is the most widely used global repository of known software and hardware vulnerabilities. If a security flaw has a Common Vulnerabilities and Exposures (CVE) ID, chances are it’s listed here.
For each CVE ID, NVD mentions the description, references to vendor advisories, severity metrics such as the Common Vulnerability Scoring System (CVSS), and classification tags like the Common Weakness Enumeration (CWE).
NIST doesn’t just catalog vulnerabilities, it also enriches them. By adding severity scoring and additional analysis, the NVD becomes more than a directory. It’s a post-disclosure intelligence hub that helps teams assess the potential impact and urgency of a given vulnerability.
How often is NVD updated?
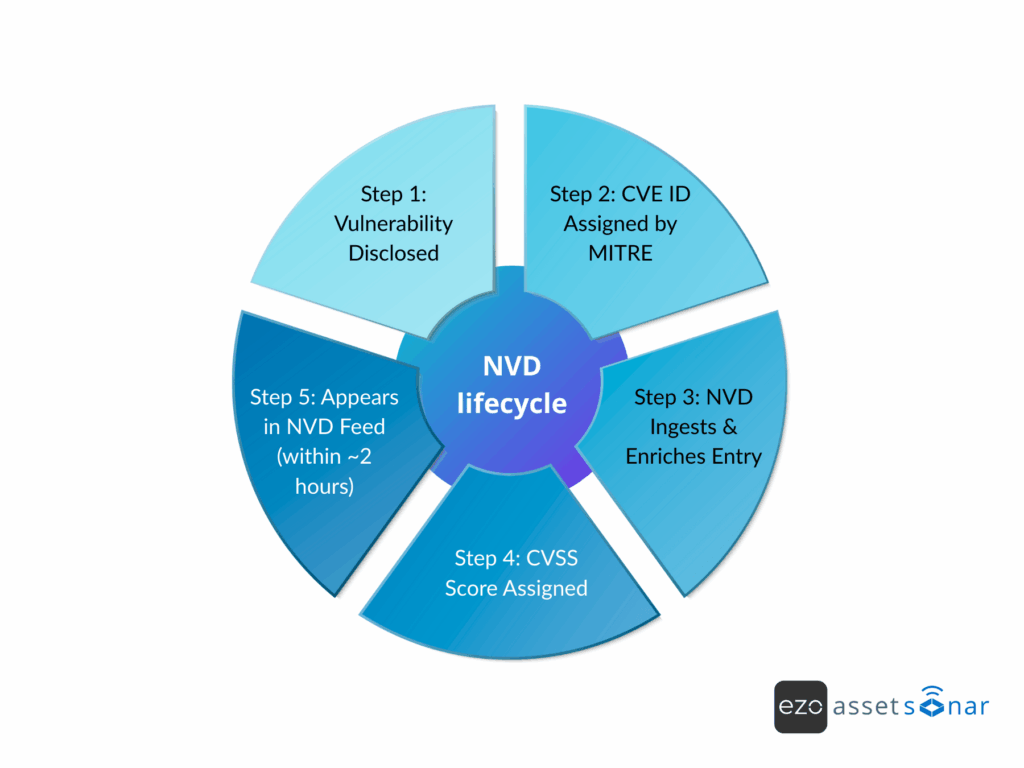
The NVD operates on a rolling basis. It processes and publishes new CVEs as they’re validated, often multiple times a day. Updates to the public feeds and APIs occur roughly every two hours, meaning most newly disclosed vulnerabilities appear in the database within hours.
In 2024 alone, tens of thousands of new entries were added, bringing the total database to over 180,000 vulnerabilities.
While high-volume days or zero-day disclosures can create short delays, especially when vendors release fixes before a full NVD entry is ready, the NVD remains the industry’s primary reference point for vulnerability data.
Why the NVD matters but isn’t the whole picture
At its core, the NVD gives you two key elements:
- The “what” – detailed descriptions of vulnerabilities, vendor references, and technical classifications.
- The “how bad” – severity ratings and CVSS scoring to help you assess risk potential.
But knowing a vulnerability’s existence and severity in a general sense is only part of the equation. To decide how urgent it is for your business, you need to go beyond NVD and CVSS. You must connect this global data to the specific assets, configurations, and operational priorities in your environment.
What is CVSS and how does it guide patching decisions?
You’ve just opened a new CVE entry, and one of the first things you notice is a line that reads: CVSS 3.1 Base Score: 9.8 (Critical). For many IT and security teams, this number becomes the starting point for patching decisions.
But what does it actually mean, and how should you interpret it in the context of your environment?
The CVSS is the industry standard for rating the severity of a vulnerability. It uses a score from 0 to 10, paired with a severity label ranging from Low to Critical. These scores provide a consistent way to measure potential risk. However, like any standard metric, the value lies in understanding its components and limits.
Breaking down CVSS metrics
CVSS scores are built from three groups of metrics—Base, Temporal, and Environmental—each designed to capture a different dimension of risk.
1. Base metrics: The core risk profile
The Base Score is the most important and reflects the inherent characteristics of a vulnerability. It considers factors such as:
- Attack Vector (AV): Can the vulnerability be exploited remotely, or does it require physical access?
- Attack Complexity (AC): Is exploitation straightforward or dependent on rare conditions?
- Privileges Required (PR): Can the vulnerability be exploited without credentials?
- User Interaction (UI): Does it require a user to take action, such as clicking a link?
- Scope (S): Can the vulnerability impact systems beyond the one it affects directly?
- Impact: Potential damage to confidentiality, integrity, and availability of the affected asset.
These inputs generate a score between 0 and 10. Many organizations tie these scores to patch SLAs. For example, requiring Critical vulnerabilities to be addressed within seven days.
2. Temporal metrics: Adjusting for real-world urgency
Temporal metrics refine a vulnerability’s severity based on conditions that can change over time:
- Exploit code maturity: Publicly available exploit code (e.g., on GitHub or Metasploit) raises urgency.
- Remediation level: A vendor patch reduces risk; an unpatched zero-day heightens it.
- Report confidence: A confirmed vulnerability from a credible source carries more weight than an unverified report.
These metrics help determine how pressing a vulnerability is right now, rather than at the time it was first reported.
3. Environmental metrics: Tailoring risk to your organization
Environmental metrics allow you to adjust CVSS scores based on your specific infrastructure and business priorities:
- Security requirements: Weigh confidentiality, integrity, or availability differently depending on the system’s purpose.
- Modified metrics: Adjust assumptions, e.g., lowering an “over the network” risk if the system is isolated or the instance is behind multiple layers of segmentation.
- Asset criticality: Elevate a moderate vulnerability if it affects a mission-critical system.
For example, a CVSS 6.5 vulnerability in your payment processing environment might take precedence over a CVSS 9.0 in a low-traffic internal portal.
CVSS in context: Versions and evolution
CVSS has evolved over time, with each version adding more nuance and precision:
- v2.0: Widely used for years but limited in its ability to reflect complex, real-world conditions.
- v3.0 and v3.1: Introduced more detailed scoring, which is now the most common version in active use.
- V4.0: Released in late 2023, adding sub-scores and refined metrics for greater granularity. Adoption is still growing, but it’s gaining traction among security teams looking for more tailored assessments.
Today, most CVEs are scored using v3.1, with v4.0 expected to see broader adoption in the coming years.
Why CVSS matters—and where it stops
CVSS provides a standardized, repeatable framework for assessing severity, giving teams a common language for discussing risk. But it’s not the full story. It doesn’t account for how a vulnerability interacts with your unique infrastructure, the exploit landscape, or your operational priorities.
The next step is moving beyond the CVSS score—integrating business context, asset criticality, and threat intelligence to identify what truly needs your attention first.
Why is severity (CVSS) not the same as risk in patch management?
You’re reviewing the latest vulnerability feed. A CVSS 9.8 (Critical) flaw jumps out, demanding immediate attention. A few lines down, there’s a CVSS 5.5 (Medium) vulnerability that you might be inclined to ignore.
But in your specific environment, the “medium” might actually be the bigger threat.
This isn’t a scoring error. It’s the reality that context is everything. Even NIST, the steward of the National Vulnerability Database, is clear: “CVSS is not a measure of risk.” It’s a standardized way to gauge severity; nothing beyond that.

Real-world risk involves more than technical impact. It’s shaped by likelihood, asset value, exploit activity, and operational priorities. Below are the key limitations of relying on CVSS scores in isolation.
1. Not all “critical” vulns are equally urgent
CVSS assumes a reasonable worst-case scenario in a generic environment. In your environment, that scenario might never apply.
- Example 1: A CVSS 9.8 remote code execution flaw in software you don’t use is irrelevant, no matter how scary the score looks.
- Example 2: A CVSS 9.0 vulnerability on isolated lab machines may be less urgent than a CVSS 7.0 flaw on your internet-facing production server.
“Asset management is not a problem until it becomes a problem. We once got hit with a six-figure Microsoft fine because we weren’t tracking what was actually deployed versus licensed. That made us realize that ‘critical’ means nothing without context.” — Lead Technology Specialist, Tech Business Services Firm
CVSS can’t see your network exposure, data sensitivity, or architectural safeguards. A “medium” vulnerability in a customer database directly exposed to the internet may pose a far greater risk than a “critical” bug buried in a redundant internal tool.
2. CVSS doesn’t capture exploit trends
The base score reflects potential exploitability, not whether attackers are actively using it today.
- A CVSS 10.0 vulnerability with no known exploits in the wild might be lower priority than a CVSS 7.5 vulnerability that ransomware groups are actively exploiting.
- In 2023, many organizations initially downplayed a “medium” severity flaw in MoveIt Transfer until news broke that a ransomware group was weaponizing it. Overnight, it became a top-tier patching priority.
Static CVSS scores often lag behind real-world developments. Temporal metrics in CVSS can adjust for factors like “Exploit code maturity”. However, NVD entries are not always updated quickly enough to reflect these live threats.
Fact: Only about 1% of all CVEs disclosed in a given year are exploited in the wild. If you prioritize solely by score, you risk chasing theoretical dangers while overlooking the small set of vulnerabilities that actually matter.
3. Asset criticality and business impact are ignored
CVSS does not consider the importance of the affected system to your business or the consequences of leaving it exposed.
- In healthcare, a vulnerability in a patient’s medical device could be life-or-death.
- In retail, a “moderate” flaw on a PCI-regulated payment system might jeopardize compliance, forcing you to treat it as urgent.
The CVSS score doesn’t know which servers host your “crown jewels,” or which assets carry regulatory implications.4.
4. Internal risk tolerance and compensating controls

CVSS cannot account for the safeguards that reduce real-world risk and are already in place in your IT environment. For instance,
- A CVSS 9.0 bug in a firewalled-off service may be effectively neutralized by your intrusion prevention system.
- Conversely, a lower-scoring flaw could become a higher priority if your specific configuration increases its impact.
These nuances, such as risk tolerance, architectural defenses, and configuration-specific exposure, are invisible to CVSS.
The bottom line
Severity ≠ risk. CVSS gives you a consistent technical baseline, but it was never meant to be the final word on prioritization.
Effective vulnerability management requires layering CVSS with:
- Asset intelligence: Knowing what you have, where it is, and how critical it is.
- Threat intelligence: Tracking which vulnerabilities are actively exploited.
- Business context: Understanding compliance requirements, operational impact, and tolerance for downtime.
Up next, we’ll explore how to combine these inputs into a data-driven patch management strategy that keeps your focus on the vulnerabilities that matter the most.
How to build a data-driven patch management strategy?
By now, you’ve seen the challenge: vulnerability data is everywhere. NVD entries, CVSS scores, vendor advisories, and security feeds flood in daily, sometimes hourly. But raw data, no matter how complete, is just noise unless you have a clear plan to turn it into action.
That’s where a patch management strategy comes in. Think of it as your operational playbook to decide what gets patched, when, and why, based on actual business risk rather than generic severity ratings.
Without this plan, teams often fall into two traps. They either chase every high CVSS score without knowing if it matters to their environment or overlook medium-severity vulnerabilities that are actively being exploited or hit critical assets.
A strong strategy keeps your patching efforts focused, predictable, and defensible—reducing the risk of firefighting while improving resilience.
Step 1: Centralize vulnerability data for faster, smarter decisions
Every strong patch management strategy starts with a single, unified source of truth for vulnerabilities. That begins by integrating the National Vulnerability Database (NVD), maintained by NIST, directly into your vulnerability management workflows.
“Right now, our vulnerability data is split across ten different tools—none of them talk to each other. We track some in Excel, some in Jira, some in AWS. What we’re missing is a single pane of glass that tells us what’s vulnerable, what’s patched, and what’s still exposed.” — IT & Cybersecurity Manager
Relying on manual checks of mailing lists and vendor pages slows detection and increases the odds of missing critical issues. Instead, automate the intake process so new threats are on your radar immediately:
- Connect your vulnerability scanners or asset management platforms to NVD APIs or live data feeds.
- Trigger automated checks the moment a new CVE is published to see if any of your assets are impacted.
- Use dashboards powered by the NVD feed to keep a real-time, consolidated view of emerging threats; ideal if these are refreshed daily or even hourly.
With this foundation in place, IT managers like you can shift from reactive firefighting to proactive prioritization. This approach flags and queues critical vulnerabilities for action the moment they appear and cuts the risk of overlooking high-impact CVEs, accelerating the time to remediation.
Step 2: Map vulnerabilities to your IT environment
Not every new CVE is relevant to you, so the next step is contextualizing vulnerabilities against your IT inventory. This requires up-to-date asset information: What software and versions are running on your servers, endpoints, network devices, etc.?
With a good asset inventory (or better, an automated scanner), you can quickly filter the flood of CVEs down to those that affect the systems you actually use. Map this out using a vulnerability assessment tool that either scans your systems and lists present vulnerabilities, or cross-references software lists against CVE databases.
For example, if CVE-2025-12345 is a Firefox browser bug and none of your company machines use Firefox, you can safely ignore it. On the other hand, if a CVE affects, say, VMware ESXi and you have dozens of ESXi servers, that one goes on your radar.
Knowing your environment – all hardware/software assets and their versions – is foundational to prioritizing patches. You can’t patch what you don’t know you have. Plus, you shouldn’t worry about vulnerabilities in things you don’t run.
“Shadow IT is a nightmare. People install software we don’t approve of—browsers, freeware, SaaS accounts—and the only time we catch it is by accident or during offboarding. If you don’t know what’s out there, you can’t possibly patch it.” — IT & Cybersecurity Manager.
This step often involves configuring your vulnerability management tool to continuously scan or receive inventory data so it can tell you, “Out of today’s 50 new CVEs, 5 apply to systems in your network.”
Step 3: Prioritize using CVSS and business context

Start with CVSS scores, but don’t stop there. A 9.8 (Critical) usually matters more than a 4.0, but the real priority depends on context.
Here’s a quick triage approach:
- Critical (9.0+) on key assets
- Top priority if it’s on mission-critical or internet-facing systems (e.g., public web server, firewall).
- Bump higher if it’s actively exploited in the wild (e.g., Log4Shell, Microsoft Exchange 2022) or flagged by CISA.
- High (7.0–8.9) on critical systems
- Is essentially more urgent than a critical issue on a low-value asset.
- Ask: “Does it store sensitive data? Is it exposed? Could it disrupt core services?”
- Medium (4.0–6.9) with high impact
- Normally fixed in the regular cycle, but escalates if it hits a high-value system or could aid fraud/attack.
- Normally fixed in the regular cycle, but escalates if it hits a high-value system or could aid fraud/attack.
- Low (<4.0)
- Usually, patch in routine cycles, unless it’s part of an active attack chain.
- Usually, patch in routine cycles, unless it’s part of an active attack chain.
The key: Combine CVSS with exploit data, asset importance, and exposure. Only a small fraction of high-CVSS vulnerabilities are ever exploited. Hence, focus on the ones that actually put your environment at risk.
Step 4: Define risk-based patch tiers and timelines
Once you know what’s hot, define clear patching tiers or buckets that guide your response. For example:
Tier 1 – Immediate action
These are vulnerabilities that pose an imminent threat, e.g., critical severity with active exploits or those affecting critical internet-facing systems. These should be patched immediately or as fast as humanly possible (in an emergency change window or an out-of-cycle patch).
Think of those cases where waiting even a week could invite disaster – those belong here.
Tier 2 – Rapid patch (soon)
Tier 2 has high-priority issues that aren’t an emergency but still important. Perhaps critical vulnerabilities on internal systems, high-severity vulnerabilities on essential systems, or anything required by compliance deadlines to fix within a set time. Set a short deadline for these and patch them within 1-2 weeks.
Tier 3 – Standard patch cycle
These include the bulk of vulnerabilities, e.g., moderate issues, non-exploited highs, etc., that should be fixed as part of normal patch cycles (perhaps in the next monthly cycle or next maintenance window). You don’t ignore them, but you can handle them without fire drills.
Tier 4 – Defer/monitor
Tier 4 includes low-risk issues that you document but perhaps defer until a convenient time or even until the next version upgrade. It may also include any vulnerability that you consciously accept the risk for a while. This could be because the fix is complex or the system is being decommissioned soon.
Keep an eye out in case something changes, like a low-severity vuln gets weaponized unexpectedly.
Having these tiers helps communicate to IT teams and management which issues are fixed when. It sets expectations. And when done right, this gets you out of the endless “patch everything now” trap.
Step 5: Deploy, track, and continuously improve
Even the smartest vulnerability prioritization won’t protect you if patches aren’t applied correctly. The goal is controlled deployment, i.e., moving fast enough to close security gaps while keeping systems stable and available.
Match speed to risk
For Tier 1 urgent issues, use fast-track testing and deploy patches to production as soon as you can. In these high-risk cases, it may be worth accepting a slightly higher chance of disruption to close the security gap quickly.
For lower-tier vulnerabilities, schedule patches during regular maintenance windows. Always test in a staging environment first, especially for critical servers. Why? Because a patch that fixes a vulnerability but causes downtime is its own incident.
Many IT teams also use a canary deployment model, i.e., patch a small group of systems and verify stability, then roll out to the rest.
Once deployment starts, track and report on its progress. Use a modern vulnerability management dashboard that provides insights like:
- Number and percentage of critical vulnerabilities remediated
- Average time to patch by severity tier
This tracking not only supports compliance frameworks that require proof of timely remediation, it also builds trust with leadership. For example, you might report:
“In the past 30 days, 95% of identified critical vulnerabilities have been patched; the remainder are scheduled due to system constraints.”
If deadlines for critical vulnerabilities are consistently missed, investigate the root cause. Are approval workflows too slow? Are maintenance windows too limited? Are specific systems creating bottlenecks? Identify and address these friction points to improve future performance.
By following a disciplined patch management process—centralizing vulnerability data, mapping vulnerabilities to assets, prioritizing intelligently, defining patch tiers, and deploying with tracking—you replace patching chaos with a targeted, risk-based strategy.
The result? You put effort where it matters most, closing “real” risks without overwhelming your IT ops.
From data to deployment: Avoiding pitfalls
Even with a clear, prioritized patch list, things can go off track once it’s time to roll out fixes. Bottlenecks, missed windows, and unexpected disruptions can all erode the value of your strategy.
Below are some of the most common challenges that IT teams face during patch deployment—and how to avoid them—so your patch management stays on schedule and delivers the protection you planned for:
1. Don’t blindly patch without due diligence
Speed matters in patching, but rushing every update straight into production can cause more harm than good. Treating every vulnerability as an all-hands emergency increases the risk of outages, broken applications, and even future hesitation to patch.
For example, firmware or OS updates sometimes introduce compatibility problems that disrupt critical services. That’s why the goal isn’t just to patch fast—it’s to patch fast and smart.
- Test first when possible: Run patches in a staging or test environment before touching production, especially for core systems.
- Have a rollback plan: Take VM snapshots or equivalent system images before patching so you can revert quickly if needed.
- Keep backups current: Maintain reliable backups of databases, configuration files, and user data so recovery is swift if an update goes wrong.
With these safeguards in place, you can apply urgent patches quickly and confidently, knowing you have a safety net that protects both uptime and security.
2. Understand the risk of delaying patches
If rushing patches can cause problems, dragging your feet can be even more costly. Delaying known fixes—whether from fear of disruption or slow internal approvals—has been at the heart of some of the most significant breaches in history.
Take the Equifax breach in 2017, for example. A critical Apache Struts vulnerability (CVE-2017-5638) had a patch available in March. Equifax left it unpatched for months. Attackers exploited it in May, leading to one of the largest data thefts ever recorded.
The MOVEit Transfer zero-day in May 2023 was similar. A ransomware gang began exploiting it within days of discovery. For MOVEit, no patch existed at first. It was a true zero-day. But as soon as mitigations and patches were released, every day of delay became high-risk.
Organizations that couldn’t act fast enough saw their data stolen and held for ransom.
The pattern is clear: attackers move quickly, and they automate scanning for newly disclosed CVEs. A working exploit for a critical flaw often appears within 24–48 hours of public disclosure. According to Ponemon Institute research, nearly 60% of breaches trace back to a known vulnerability that had not been patched.
The takeaway? Time-to-patch matters. If a vulnerability is already being exploited in the wild, the small risk of disruption from an emergency patch is far better than the fallout from a full-scale breach.
Treat those cases as “patch now” moments, and make sure your processes can move just as fast as the attackers.
3. Use maintenance windows and phased rollouts whenever possible
Not every vulnerability demands an all-hands, immediate fix. For lower-risk patches, work with your IT ops team to apply updates during planned maintenance windows or periods of low usage.
This keeps disruption to a minimum while still closing gaps in a timely way.
Roll updates out in phases. Patch a small group first, typically around 10% of systems, and watch for issues before continuing. This “canary” approach is especially valuable for user-facing updates like web browsers or client applications, where unexpected problems could affect productivity across the business.
By staging rollouts, you catch potential issues early and avoid turning a routine patch into a large-scale interruption.
4. Consider automation vs. manual patching judiciousl
Automation can be a powerful force multiplier in patch management. The right tools can push updates to hundreds or thousands of machines in minutes, cutting down both workload and time-to-deploy.
It’s especially effective for routine, well-tested patches in consistent environments. Example includes rolling out monthly Windows security updates to all domain-joined PCs overnight with minimal disruption.
But automation isn’t a one-size-fits-all solution. Sensitive systems and bespoke applications often require a more deliberate touch. Some patches may need to be applied in a specific order with custom configuration checks, or under tightly controlled conditions to avoid downtime.
The key is to clearly define in your patch strategy which updates get automated and which require manual handling:
- Automate these for breadth and speed: User workstations and standardized systems where the risk of not patching is higher than the risk of a minor compatibility hiccup.
- Apply manual control for such critical infrastructure: Servers, production systems, and high-availability environments where uptime and change control are paramount.
Pro tip: Find the balance that works for your environment. Use automation to cover the wide ground quickly, but reserve manual processes for the systems where precision and stability matter most.
This approach keeps you fast where you can be and careful where you have to be.
“Automation is key for us. With such a small team, we can’t manually push every update. We use Intune and Co-Pilot for routine patching, but for critical servers, we still insist on hands-on testing before deployment.” — IT & Cybersecurity Manager.
5. Beware of “patching fatigue” and alert overload
If every vulnerability is treated as a “drop everything” emergency, your team won’t just burn out; they’ll start tuning out alerts altogether. That’s why prioritization is essential. By filtering out the noise, you can reserve the all-hands response for issues that are truly urgent.
A practical way to do this is to build a clear escalation process. In your ticketing system or IT asset management (ITAM) tool, tag critical or emergency patches differently from routine updates.
That way, everyone knows when it’s time to shift gears and patch immediately versus when a fix can safely wait until the next cycle. This discipline prevents alert fatigue and keeps your patching program sustainable.
The goal is to balance speed with stability:
- Patch fast when the threat is high—but with safeguards like testing, phased rollouts, and rollback plans.
- Avoid letting slow approval processes hold up patches that truly need immediate action.
Your patch policy should include a fast-track route for security fixes that bypasses unnecessary red tape when the risk is high.
Finally, the right tools make it easier to keep this balance. Modern vulnerability management platforms can act as a “vulnerability control tower”—helping you prioritize threats, automate where possible, and keep patching under control without overwhelming the team.
“We don’t need more alerts. We need better reporting. Data entry means nothing without data out.” — Lead Technology Specialist.
How modern tools help: The need for a “vulnerability control tower”
Tracking thousands of vulnerabilities, mapping them to the right assets, and coordinating fixes across the entire organization is no small task.
Modern vulnerability and patch management tools are built to take that weight off your shoulders, giving you a centralized “control tower” view of your entire risk landscape.
Here’s how today’s solutions can power up your patch strategy:
1. Real-time integration with NVD and threat feeds
The best patch management tools automatically sync with trusted sources like the NVD, vendor advisories, and live threat intelligence feeds. That means the moment NIST publishes a new CVE with its CVSS score, your system already knows.
Some enterprise platforms go further by integrating with databases of known exploited vulnerabilities, like CISA’s KEV catalog, to tag issues that attackers are actively using. Instead of manually cross-referencing CVEs with news, the platform can flag:
“This high-severity vulnerability is being exploited. Treat as priority 1.”
This real-time visibility works like having a radar for your tech environment, helping you navigate thousands of vulnerabilities without flying blind.
2. Automated asset-vulnerability mapping
Modern patch management tools keep a current inventory of your hardware and software, often by running regular network scans. When a new vulnerability is published, the tool can instantly match it to the devices, applications, or systems in your environment that are affected.
For instance, if an OpenSSL vulnerability drops, a good platform will immediately show: “Systems affected: WebServer01, AppServer07” based on version fingerprints. This not only saves analysts hours of manual work but also cuts the risk of missing something critical.
In seconds, you get a clear answer to the question, “Are we affected?” Some tools go even further with agent-based endpoint scanning, detecting vulnerable software versions in real time.
3. Prioritization intelligence and dashboards

Remember our discussion on context-based prioritization? Many modern vulnerability management platforms now handle that automatically.
They use built-in risk scoring that blends CVSS severity, exploit intelligence, and asset criticality—often letting you tag specific systems as “critical assets”—to produce a prioritized list or overall risk metric.
Instead of sorting only by CVSS, the platform can rank vulnerabilities in your environment by true business risk. Your dashboard might highlight “Top 10 Riskiest Vulnerabilities”, mixing a couple of critical CVEs with high-severity issues on very sensitive systems.
This at-a-glance view ensures important items don’t get lost in raw score lists. Visuals like heat maps showing which hosts have the most critical issues. Similarly, trend lines that track outstanding vulnerabilities give you quick, data-driven insight for faster patching decisions.
4. Orchestrated patching and workflow
The end goal of any vulnerability program is patching, and many modern tools now connect directly to patch management workflows.
Some vulnerability scanners can trigger deployments through integrations with platforms like Microsoft Endpoint Manager, WSUS, SCCM, or third-party patching tools.
Others at least track progress, marking vulnerabilities as remediated once patches are applied.
The most advanced platforms act as an end-to-end “Vulnerability Control Tower”—letting you see an issue, click to deploy the patch to affected systems, and track the entire process in one interface.
While you still need proper change control, tight integration can significantly reduce the gap between “identified” and “remediated” by automating the handoff to the systems that apply the fixes.
5. Automation with safeguards
As we covered earlier, automation can take a lot of the heavy lifting out of patching. Modern tools let you set policies like “auto-apply patches for Critical vulnerabilities on low-risk systems” while keeping a manual approval step for higher-impact changes.
You can schedule recurring scans and auto-patching to run during defined maintenance windows, with alerts if something fails.
This way, the repetitive work—like deploying an OS update to 1,000 machines—happens automatically, while you still have full visibility and the ability to step in when needed.
6. Contextual guidance and reporting
A good vulnerability or patch management tool does more than just list problems; it gives you the context to act. When you view a vulnerability in the dashboard, you might see a plain-language summary of its nature, why it matters, and whether there are known exploits or active malware using it.
Many tools even link to real-world examples, e.g., “This flaw was leveraged in the WannaCry outbreak” or “APT Group X has exploited this in the wild.” That context makes it easier to explain to leadership why a patch is urgent.
Strong reporting features add another layer of value. You can quickly produce management-ready reports showing patch coverage, compliance status (such as meeting a policy to patch critical vulnerabilities within X days), and progress trends.
The next time you meet your CIO/CSO, you can confidently say:
“We reduced unpatched critical vulnerabilities by 80% in Q1.”
Think of these tools as your Vulnerability Control Tower:
- Visibility – All vulnerabilities and assets in one place.
- Context – CVSS scores, exploit data, and business criticality in one view.
- Tackle – The ability to remediate or track fixes from the same interface.
Whichever tool you choose, configure it to pull in the right data sources (NVD, CVSS, threat intelligence) and reflect your environment’s priorities.
The most advanced setups use automation to handle the repetitive work, freeing analysts to focus on decisions and exceptions rather than manually rummaging through spreadsheets of CVEs.
Used this way, these tools don’t just track vulnerabilities; they multiply your team’s effectiveness.
TLDR: Key takeaways for IT Managers
We’ve covered a lot of ground. Now let’s boil it down. For busy IT managers who want to strengthen their patch management approach, here are the key points to remember:
1. NVD and CVSS are essential data sources, but just the start
The NVD tells you what vulnerabilities exist and provides the details. CVSS gives you a baseline sense of how bad each one is in general terms. Both are essential starting points for any vulnerability management program.
But don’t treat a CVSS score as the final word on risk. It’s baseline data—valuable, but only complete when you layer in your organization’s context.
2. Turn data overload into actionable intelligence
With hundreds of new vulnerabilities disclosed each week, it’s easy to feel overwhelmed. Don’t let the volume stall you. Put processes in place to filter and prioritize so you focus only on threats that genuinely matter to your environment.
That means knowing your assets, understanding what’s actually exploitable, and zeroing in on the critical items. This approach cuts through 95% of the noise so you can concentrate on the small percentage that poses real risk to your systems.
3. Severity ≠ risk. Always apply context
Make it clear to your team: a high severity score is a signal, not an automatic decision. Encourage analysts to dig deeper and ask questions like, “Do we run this software? Where is it deployed? Is it exposed? Are attackers targeting it?”
By making risk-based decisions, you’ll improve patch outcomes and close the most dangerous gaps first instead of chasing the highest numbers on the list.
4. Establish a risk-based patch strategy and policy
A formal patch management policy that factors in risk, such as setting timelines based on severity and asset criticality, creates clarity and consistency. Suppose everyone knows that “Critical vulnerabilities on servers must be patched within 7 days, and ‘critical’ means high CVSS or systems that are internet-facing or data-sensitive”. In that case, it becomes part of your team’s culture and daily workflow.
The strategy we’ve covered—centralizing data, mapping assets, setting prioritization tiers—should be documented and agreed upon.
This not only streamlines day-to-day operations but also makes audits and compliance checks easier, proving you have a structured, risk-based approach in place.
5. Use tools and automation, but maintain oversight
Manually tracking and remediating every vulnerability is a losing battle. Invest in tools that can handle the heavy lifting—tracking issues and, in some cases, applying patches automatically.
Let automation take care of repetitive jobs while keeping human oversight for critical decisions and exceptions. It’s not “set and forget”, it’s “set, monitor, and step in when needed.”
Let the patch management tool surface the most important issues and coordinate fixes, while you focus on steering the process at a high level.
6. Patch management is a continuous, proactive process
With new threats surfacing daily, patching needs to be an ongoing process. This calls for monitoring newly disclosed vulnerabilities (subscribe to NVD or vendor security bulletins for this), regularly scanning your environment for missing patches, and tracking your patching performance.
Focus on continuous improvement. Shorten your average time to patch critical vulnerabilities, increase coverage across all systems (including that forgotten server in the closet), and close gaps faster.
Be proactive! Retire or upgrade legacy systems, cut your attack surface by removing unused software, and use virtual patches or mitigations when a full fix isn’t immediately available.
7. Don’t forget the human element
A patch strategy only works when the people executing it understand its purpose. Educate your IT staff and application owners on the “why” behind patching, not just the what. When everyone sees patches as critical risk-reduction measures—not just another chore—it changes the mindset.
Celebrate wins, like avoiding impact from a zero-day because you patched quickly. Foster collaboration between security teams (who find vulnerabilities) and ops teams (who apply fixes). When done right, patching shifts from tension—“Security is nagging us again”—to teamwork—“We’re all working to keep the organization safe and running smoothly.”
By acting on prioritized intelligence instead of drowning in endless lists, you can turn vulnerability management into real risk reduction.
The gap between an organization that simply knows about thousands of issues and one that quickly mitigates the right ones can be the difference between resilience and disaster.
You’ve seen how NIST, CVSS, and business context fit together to shape a risk-based patch management strategy. But turning insights into daily practice can feel overwhelming. To make it easier, we’ve created a simple checklist you can use to keep your team focused on the next steps.
Frequently Asked Questions
What is CVSS and how is it used in vulnerability scoring?
CVSS (Common Vulnerability Scoring System) is a 0-10 metric that assesses severity of vulnerabilities. It helps teams decide which issues to patch first.
Why do some users say CVSS is “flawed” or “dead”?
Because CVSS alone doesn’t consider real exploitability or context. Many vulnerabilities with high CVSS never get exploited.
What additional scoring systems complement CVSS?
EPSS (Exploit Prediction Scoring System) or KEV (Known Exploited Vulnerabilities) are often used alongside CVSS to capture real-world risk.
How do organizations prioritize patches under NIST guidelines?
They use CVSS scores, business criticality, exposure (internet accessibility), and ease of exploit. High severity + high exposure get higher priority.
Are there NIST or CMMC standards defining how fast patches must be applied?
Some references suggest using FedRAMP-style timelines (30/90/180 days for high, moderate, and low vulnerabilities) but many organizations adapt based on criticality.
Who is responsible for patching vulnerabilities?
The system owner typically owns the risk and patching responsibility; IT/Security teams support detection, prioritization, and coordination.
What features are essential in a good patch-management strategy?
Essential features: automatic discovery of assets, vulnerability scanning, usage of CVSS + contextual prioritization, remediation tracking, rollback plans.
How often should vulnerability scans and patching occur?
Vulnerability scans should be frequent (e.g. weekly/monthly) depending on exposure; patches ideally should follow soon after critical vulnerabilities are identified.
How to handle legacy or unsupported systems that can’t be patched?
Mitigate via compensating controls: isolation, reduced access, network segmentation, use of firewall/WAFs; plan replacement if possible.
What are common challenges in implementing patch-management in large environments?
Challenges: coordinating across teams, ensuring all assets are inventoried, avoiding disruption, dealing with false positives, managing dependencies.
How to balance patch urgency vs system stability?
Test patches first in staging, assess potential impact, schedule low critical patches during maintenance windows, prioritize real risk vs theoretical severity.
How do you decide what “severity” means in your environment?
Define business critical assets, data sensitivity, user impact; use CVSS environmental modifiers + internal metrics (asset criticality, exposure).
What metrics or KPIs help measure effectiveness of patch strategy?
Metrics: time to remediate high severity vulnerabilities, percentage of patched systems, number of reopen incidents, patch failure rates.
What role does documentation and policy play in patch management?
Clear policies define responsibilities, timelines, patch scopes; documentation supports auditability and helps when coordinating multiple teams.
How can EZO / AssetSonar support a strong patch management & CVSS-based strategy?
They provide asset inventory, vulnerability tracking, dashboards for CVSS scores + exploit potential, alerting for overdue patches, historical audit logs to show compliance and risk posture.






