
Imagine yourself in the shoes of a COO running a large fleet operation. Every quarter, the same questions come up:
Why are we still dealing with unplanned equipment downtime?
Why do maintenance costs keep rising, but fleet reliability isn’t improving?
And why does every major breakdown feel like a surprise?
On paper, everything looks under control. Preventive schedules are in place. Equipment is tracked. Maintenance teams are assigned.
But when a critical machine fails on-site, the reality is very different.
Technicians often don’t have the full context of the equipment. They’re working with partial information, scattered service records, incomplete usage data, and limited visibility into operating conditions. Work begins only after the failure has already impacted operations.
From a leadership perspective, this isn’t just a maintenance issue; it’s an execution problem.
Most teams don’t choose reactive maintenance. They end up there because the system around them doesn’t give them better options.
A crane breaks down. An excavator goes offline. A site reports an issue. The team responds, fixes it, and moves on until the next failure. Over time, this becomes the default mode: reacting instead of planning.
So leadership pushes for preventive maintenance. Schedules are enforced. Compliance improves. But so does downtime from planned servicing, and the gap between effort and actual reliability remains.
Then comes predictive maintenance. The expectation is clear: use equipment data to stay ahead of failures. But without accurate, connected data across telematics, service history, and operations, predictions don’t translate into action.
This is where most enterprise operations get stuck. They’re not choosing between reactive, preventive, or predictive maintenance; they’re operating across all three, without a system that can execute any of them consistently.
So the real question isn’t which strategy is best. It’s what actually works when you’re responsible for uptime, cost control, and operational risk across an entire fleet.
Why maintenance strategy breaks at enterprise scale
Maintenance doesn’t fail because the ideas are flawed. It fails because execution breaks down with increasing complexity.
In most large-fleet environments, equipment data, maintenance records, and service workflows reside in separate systems. Telematics platforms track machine performance, EAM systems manage work orders, and inspection logs or schedules often sit in spreadsheets or disconnected tools. These systems rarely operate as a single, real-time source of truth.
That disconnect creates blind spots for maintenance teams. Decisions are made without a complete view of the equipment, no clear visibility into how a machine is being used, what it has gone through, or what condition it’s currently in.
In practice, this leads to inefficient outcomes. Some machines are over-maintained because they follow rigid schedules, while others are under-maintained because no signal surfaces the need for intervention. Critical failures are often detected too late, after they disrupt operations, while non-critical maintenance consumes valuable technician time.
This is the paradox many large-scale operations face: they’re doing more maintenance, but achieving less reliability.

What is reactive maintenance? And where it still makes sense
Reactive maintenance is the most basic form of maintenance. Something breaks, and the team fixes it. There’s no planning involved, only response.
In many operations, this still plays a practical role. For low-cost or easily replaceable equipment, it often makes more sense to let them run until failure rather than invest time in monitoring or scheduled servicing.
For example, small tools, attachments, or non-critical components on a job site, like drill bits, minor fittings, or detachable accessories, are often replaced only when they fail. The cost and effort of maintaining them proactively would outweigh their value. In these cases, reactive maintenance is perfectly acceptable.
The problem arises when reactive maintenance becomes the default across all equipment types. When critical machines, such as excavators, cranes, or generators, are managed reactively, the cost of failure increases significantly. Unexpected breakdowns can halt entire job sites, delay projects, increase safety risks, and lead to costly downtime.
At scale, reactive maintenance is less of a strategy and more of a signal. It usually points to gaps in visibility, weak equipment tracking, or disconnected systems. Teams aren’t choosing to react; they’re forced to, because they lack the data and structure to act earlier.
Reactive maintenance has its place, but only when used intentionally, not by default.
What is preventive maintenance? And where it starts to break down
Preventive maintenance brings structure into operations. Instead of waiting for failures, teams service equipment based on fixed schedules or usage thresholds.
This approach is widely adopted because it creates predictability. Teams can plan workloads, allocate resources in advance, and stay aligned with compliance requirements. Maintenance becomes something you can control, not just react to.
In practice, this often looks like scheduled crane inspections, excavator oil changes, hydraulic system checks, and routine servicing for loaders, generators, and other jobsite equipment.
Consider a fleet of heavy equipment operating across multiple job sites. Every excavator is scheduled for servicing every 250 hours; filters are replaced, fluids are checked, and components are inspected. On paper, this ensures consistency.
But in reality, not all equipment operates under the same conditions. An excavator working continuously on a high-load construction site may experience wear and overheating well before 250 hours. Another machine used intermittently on lighter tasks may not need servicing even after crossing that threshold. Both follow the same schedule, but their actual maintenance needs are completely different.
Initially, preventive maintenance reduces unexpected failures and improves control. Teams feel more organized, and risks appear more manageable. But over time, cracks start to show.
The core issue is simple: Schedules are static, but equipment behavior is not. Machines don’t degrade at the same rate. Usage varies. Operating environments change. But preventive maintenance assumes a one-size-fits-all pattern.
This creates a mismatch:
- Some equipment is over-serviced, increasing costs and unnecessary downtime
- Others are under-serviced, raising the risk of unexpected failures
Teams end up doing more work, but not necessarily the right work.
Preventive maintenance still improves reliability, but only to a certain extent. Beyond that, it starts creating operational overhead without delivering proportional gains in performance or uptime.

What is predictive maintenance, and why is it hard to get right
Predictive maintenance is designed to overcome the limits of preventive maintenance. Instead of relying on fixed schedules, it uses real-time equipment data and operating conditions to determine when maintenance should happen.
This data can come from multiple sources: telematics, sensor readings, engine diagnostics, usage hours, vibration levels, and temperature patterns. When the system detects early signs of wear or failure, it triggers action before the equipment breaks down.
In theory, this is the most efficient approach. It reduces unnecessary servicing, minimizes unplanned downtime, and aligns maintenance with how equipment is actually used in the field.
Consider a fleet team managing excavators across multiple construction sites.
Instead of servicing every machine at fixed intervals, the team monitors:
- engine temperature fluctuations
- hydraulic pressure levels
- abnormal vibration patterns
- operating hours under heavy load
One excavator starts showing rising engine temperatures and unusual vibration over several days. The system flags this pattern and automatically creates a maintenance work order.
The technician reviews the full context: recent workload intensity, operating conditions, past breakdowns, and service history, and identifies early signs of engine component wear. The issue is addressed before it becomes a costly failure or results in site downtime.
That’s predictive maintenance working as intended.
But in practice, most teams struggle to reach this level of execution. The biggest challenge isn’t the concept or the technology; it’s the data.
Predictive systems depend on accurate, complete, and connected equipment data. But in many operations:
- Equipment records are outdated or incomplete
- Telematics and monitoring systems are not fully integrated
- Maintenance history is scattered across spreadsheets or disconnected tools
Without this foundation, the signals become unreliable.
For example, if a machine isn’t properly linked to its service history, usage patterns, or past failures, the system may either trigger false alerts or miss critical warning signs entirely.
This creates a trust gap. Teams see alerts but don’t act on them confidently. Over time, predictive systems get ignored or underutilized.
Another common issue is over-investment in dashboards without operational integration. Teams can see equipment data, but can’t act on it easily. There’s no direct link between insight and execution, no automatic work orders, no connected workflows.
Predictive maintenance works, but only when the underlying system is robust enough to support it.
That means:
- clean, reliable equipment data
- connected systems across EAM, telematics, and maintenance workflows
- and automation that turns signals into action
Without this, predictive maintenance remains a concept rather than a true operational advantage.
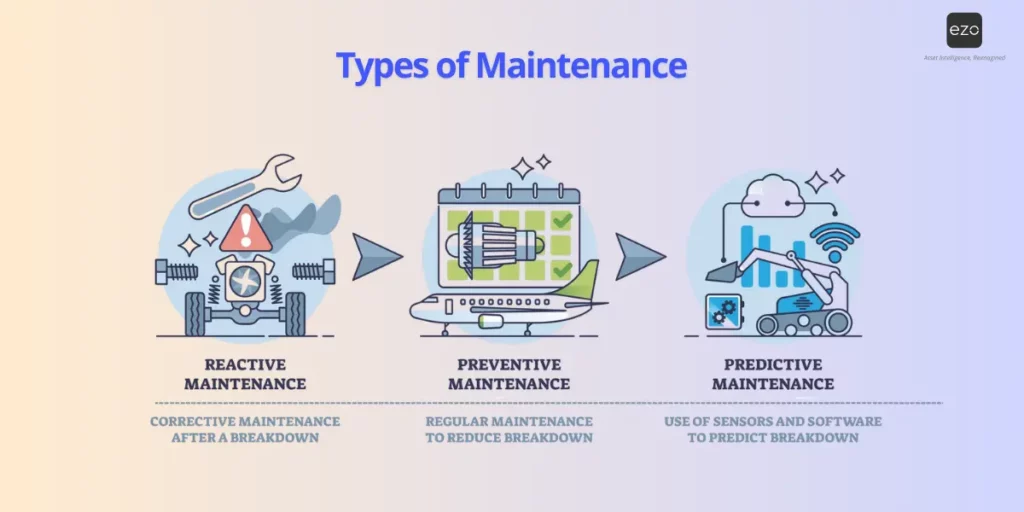
Reactive vs preventive vs predictive: What’s the real difference?
At a high level, the difference between these strategies comes down to how decisions are triggered.
Reactive maintenance is triggered by failure. Preventive maintenance is triggered by time or usage. Predictive maintenance is triggered by actual conditions.
Each approach has its place, but they vary significantly in terms of efficiency, risk, and scalability.
Reactive maintenance requires less planning data upfront, but repairs still depend on knowing what failed, where the asset is, which parts are needed, and who is available. Preventive maintenance adds structure, while predictive maintenance improves efficiency when asset data and integrations are reliable.
Understanding these differences is important, but more importantly, it highlights why no single strategy is sufficient on its own.
What actually works: The hybrid model
In real-world operations, maintenance strategies are not mutually exclusive. High-performing teams use a combination of approaches, applied intentionally based on equipment type, usage, and criticality.
For example, a fleet operating across multiple construction sites doesn’t treat every piece of equipment the same. Low-impact assets, such as small tools or attachments, are handled reactively; if they fail, they’re repaired or replaced with minimal disruption.
Standard equipment, such as loaders or backhoes used in routine operations, typically follows a preventive approach. These machines are serviced at defined intervals, based on operating hours, inspections, and compliance requirements, to maintain baseline reliability.
But when it comes to critical equipment, excavators on high-dependency projects, cranes, or generators powering entire sites, the approach shifts to predictive maintenance. These assets are continuously monitored for performance signals, and maintenance is triggered before failures impact operations.
This is how maintenance actually works at scale, not as a single strategy, but as a layered approach.
- Reactive maintenance is used for low-value or non-critical assets where the cost of failure is minimal
- Preventive maintenance provides a baseline level of reliability and ensures safety and compliance
- Predictive maintenance is reserved for critical equipment where downtime has a direct operational or financial impact
This hybrid approach allows teams to balance efficiency with risk. It avoids over-maintaining simple assets while ensuring critical equipment gets the attention it demands.
However, adopting a hybrid model isn’t just about defining strategies. It requires a system that can support different triggers, usage hours, condition-based signals, inspections, and breakdown events, while connecting them to the right workflows without adding operational complexity.
The real problem isn’t strategy; it’s execution
Most organizations already understand these strategies. The challenge lies in executing them consistently and effectively.
Execution breaks down when systems are disconnected. Maintenance tasks are created manually, asset data is incomplete, and workflows are not aligned with real-time conditions.
Without a unified system, teams rely on manual coordination, which introduces delays, errors, and inconsistencies. Decisions are made based on partial information, and actions are often reactive, even when the intent is preventive or predictive.
Execution requires more than just processes. It requires a foundation where data, workflows, and automation are connected.
The missing layer: Asset context
At the core of effective maintenance is context. Every decision depends on understanding the equipment in question; its service history, utilization, operating conditions, dependencies, and current health.
Without this context, technicians are forced to troubleshoot blindly. They rely on assumptions, manual logs, or fragmented data spread across systems.
For example, a work order comes in: “Excavator overheating on site.”
Without context, the technician starts checking multiple possibilities, coolant levels, hydraulic systems, engine load, and ambient conditions, trying to piece together what might be wrong. This takes time and often leads to trial-and-error fixes or unnecessary part replacements.
With context, the situation changes completely. The technician opens the work order and immediately sees that the excavator has logged extended high-load hours over the past week, recently missed a scheduled maintenance check, and has a history of overheating under similar conditions. Now, as you can see, the root cause becomes clearer, and the fix is faster and more precise.
A technician can instantly access the asset’s service records, usage trends, inspection logs, and prior breakdowns, all in one place. This allows them to diagnose issues faster, avoid guesswork, and take the right action the first time.
Context transforms maintenance from reactive firefighting into informed, proactive decision-making.
How high-performing enterprise teams actually operate
Leading enterprise teams don’t rely on static processes. They build systems where maintenance is embedded into day-to-day operations, not treated as a separate function.
In these environments, maintenance actions are triggered automatically based on real equipment conditions. Machine data flows continuously from telematics, inspections, and usage logs, while maintenance workflows are tightly connected to that data.
For example, if an excavator starts showing abnormal engine temperature or excessive vibration, the system automatically generates a maintenance work order. The assigned technician doesn’t start from scratch; they receive full context: operating hours under load, recent site conditions, past breakdowns, and service history.
Once the issue is resolved, the equipment record is automatically updated to capture what was fixed, what caused it, and how the machine is performing afterward. This creates a continuous feedback loop where every action improves future decision-making.
This level of integration reduces manual effort, eliminates guesswork, and ensures that maintenance actions align with how equipment actually operates in the field.
Where most maintenance strategies fail
Despite best intentions, many maintenance strategies break down for the same underlying reasons.
Equipment data is often incomplete or outdated. Usage hours aren’t logged consistently, inspection reports are delayed, and service histories are scattered across systems. Workflows depend heavily on manual inputs, introducing gaps, delays, and inconsistencies.
At the same time, core systems operate in silos. Telematics platforms track machine performance, EAM systems manage work orders, and site teams maintain their own logs. Without a unified view, maintenance teams never see the full picture of how equipment is actually performing.
The result is predictable:
- critical issues go unnoticed until failure
- routine maintenance is performed unnecessarily
- and visibility into fleet health remains limited
These failures aren’t due to a lack of strategy. They happen because the systems meant to support that strategy aren’t aligned.
How to choose the right approach. Without overcomplicating it
Choosing the right maintenance approach doesn’t require complex frameworks. It starts with understanding the role each piece of equipment plays in your operations.
Teams should evaluate a few key factors: how critical the equipment is to the job, the cost of failure, the intensity of its use, whether reliable data (telematics, inspections) is available, and whether maintenance actions can be triggered automatically.
Based on this, the right approach becomes clear:
- Reactive maintenance for low-impact assets like small tools or easily replaceable components
- Preventive maintenance for standard equipment with predictable usage and compliance requirements
- Predictive maintenance for high-value, high-dependency machines where downtime directly impacts operations
The goal isn’t to optimize every machine in isolation. It’s to build a balanced system, one that applies the right level of effort where it matters most, without over-engineering the rest.
What’s changing: From maintenance to asset operations
Maintenance is no longer a standalone function. It’s becoming part of a broader operational model in which equipment, operators, job sites, and workflows are interconnected.
This shift marks a move from managing individual maintenance tasks to managing entire equipment operations. Maintenance is just one layer within a larger system focused on uptime, utilization, cost control, and operational visibility.
In this model, decisions aren’t made in isolation. They’re driven by real-time equipment data, usage hours, operating conditions, site demands, and executed through connected workflows.
A work order isn’t just a response to a breakdown. It’s part of a continuous system where equipment performance, maintenance actions, and operational outcomes are all linked.
The result is a more controlled, predictable operation in which maintenance supports the business rather than reacting to it.
Why asset-led systems work better
When maintenance is built on top of equipment data, everything becomes more aligned. Decisions are based on accurate information, actions are triggered automatically, and outcomes are measurable. Teams spend less time coordinating and more time executing.
For example, consider a field scenario where a site reports: “Excavator performance has dropped.”
In a disconnected setup, this turns into back-and-forth. The maintenance team checks logs, calls the operator, looks up service records in separate systems, and tries to piece together what might be wrong before taking action.
In an asset-led system, the work order is already linked to the machine. The technician can instantly see operating hours, recent workloads, past maintenance history, inspection reports, and any recurring issues. They know exactly what the equipment has gone through before stepping on-site.
If required, automation can even trigger predefined actions, like scheduling inspections, ordering parts, or assigning the right technician, based on the equipment’s condition and usage patterns.
Platforms like EZO enable this by connecting asset management with maintenance workflows. Every action is tied to real equipment conditions, and automation ensures work is executed without unnecessary delays.
This approach shifts maintenance from a reactive function to a proactive, integrated part of operations, where decisions are driven by context rather than guesswork.
Conclusion: Stop choosing strategies. Start building systems
Reactive, preventive, and predictive maintenance are not competing strategies. They are complementary approaches, each solving a different part of the problem depending on equipment criticality, usage, and risk.
Most enterprise teams already have some version of all three in place. The issue is not the absence of strategy; it’s the lack of a system that can bring them together and execute them consistently.
Because at scale, the challenge isn’t deciding what to do. It’s ensuring that the right action happens at the right time, triggered by the right signals, and executed with full context.
Without that system, even the best strategies fall apart:
- Reactive becomes firefighting
- Preventive becomes overhead
- Predictive becomes noise
But when maintenance is built on connected asset data, integrated workflows, and automation, these same strategies work together rather than against each other.
That’s when teams move from:
- chasing breakdowns → preventing them
- managing work orders → running fleet operations
- reacting under pressure → executing with confidence
At enterprise scale, maintenance isn’t about theory. It’s about execution; reliable, repeatable, and grounded in real equipment data.
The shift is simple, but critical: Stop choosing strategies. Start building systems that can execute them.







